Overview
CTM-AI operationalizes the Conscious Turing Machine (CTM) into a practical system: many parallel processors, a limited-capacity workspace, global broadcast, and learned links for multimodal integration.
System Demos
Minimal Case Demo
Sarcasm Case Demo
What is CTM-AI?
A concrete blueprint that translates CTM theory into a modular, testable AI system.
CTM-AI implements a global-workspace architecture inspired by the formal Conscious Turing Machine. Instead of relying on a single monolithic model or a fixed multi-agent script, CTM-AI uses a large collection of processors (LLMs/VLMs/tools/memory modules) that compete to contribute information; the winning “chunk” enters a small workspace and is broadcast back to all processors, while links form over time to enable fast unconscious information sharing.
System Architecture
CTM-AI follows the CTM 7-tuple: <STM, LTM, Up-Tree, Down-Tree, Links, Input, Output>. In practice:
- LTM processors: modules with private state and an
execute / read / writeinterface that output chunks (gist, follow-up question, confidence weight). - STM workspace: a stateless “supervisor” LLM that consumes the winning chunk + user query to produce the final action/answer and a confidence score.
- Up-tree / Down-tree: selection into STM and global broadcast back to all LTMs.
- Links: dynamic edges between processors to support iterative, cross-processor fusion.
This structure generalizes single-model reasoning (when only one processor is active) and supports multimodal + tool-using behavior through the same competition-and-broadcast loop.
Core Dynamics
Collect → Compete → Broadcast → Link & Fuse → Feedback
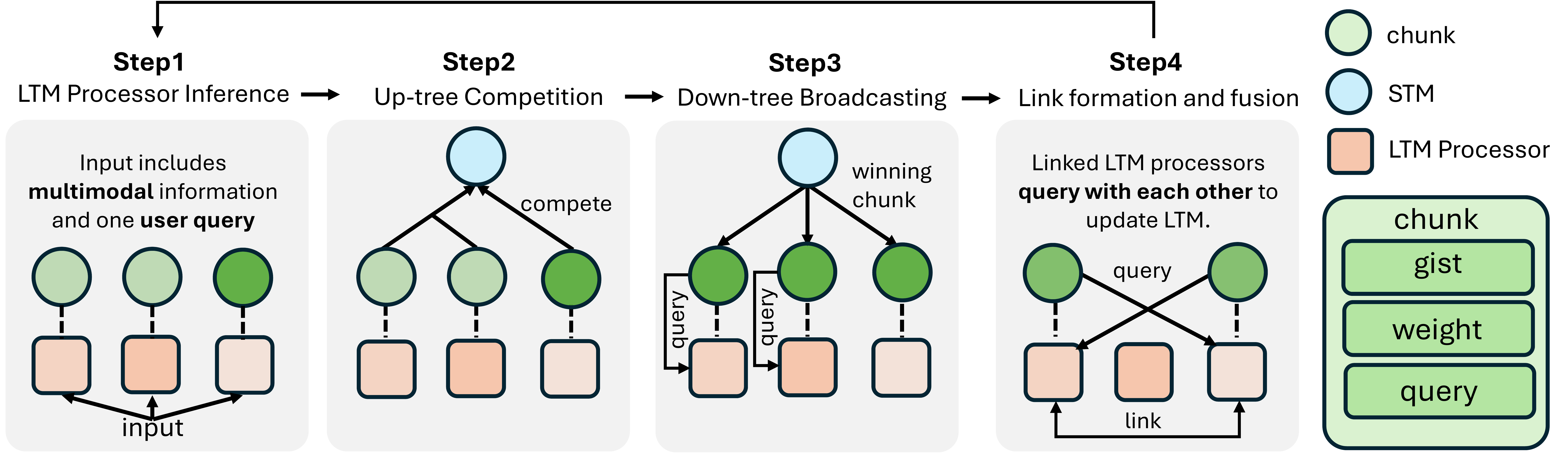
1) Chunk Collection (Parallel)
All processors observe the query (and their modality/tool context) and output a chunk:
- gist: a short English summary useful for the query
- additional_question: what information to ask other processors for
- weight: relevance/confidence-based score for competition
2) Up-tree Competition (Selection)
A single chunk is selected into the workspace (STM). In the implementation, selection can be simplified to a global argmax over weights when few processors are active.
3) Down-tree Broadcast (Attention)
The winning chunk is broadcast to all processors and written into their private memories, aligning context for the next iteration.
4) Link Formation & Fusion
Links form when another processor answers the winner’s follow-up question with high relevance; linked processors exchange answers to enrich each other’s memory for deeper multimodal/tool reasoning.
Efficiency (per iteration)
If there are K processors and L links, one iteration performs about 2(K + L) processor calls. Most stages are parallelizable; time is dominated by API/model calls (roughly “3 calls worth” per iteration), with 1–3 iterations typical.
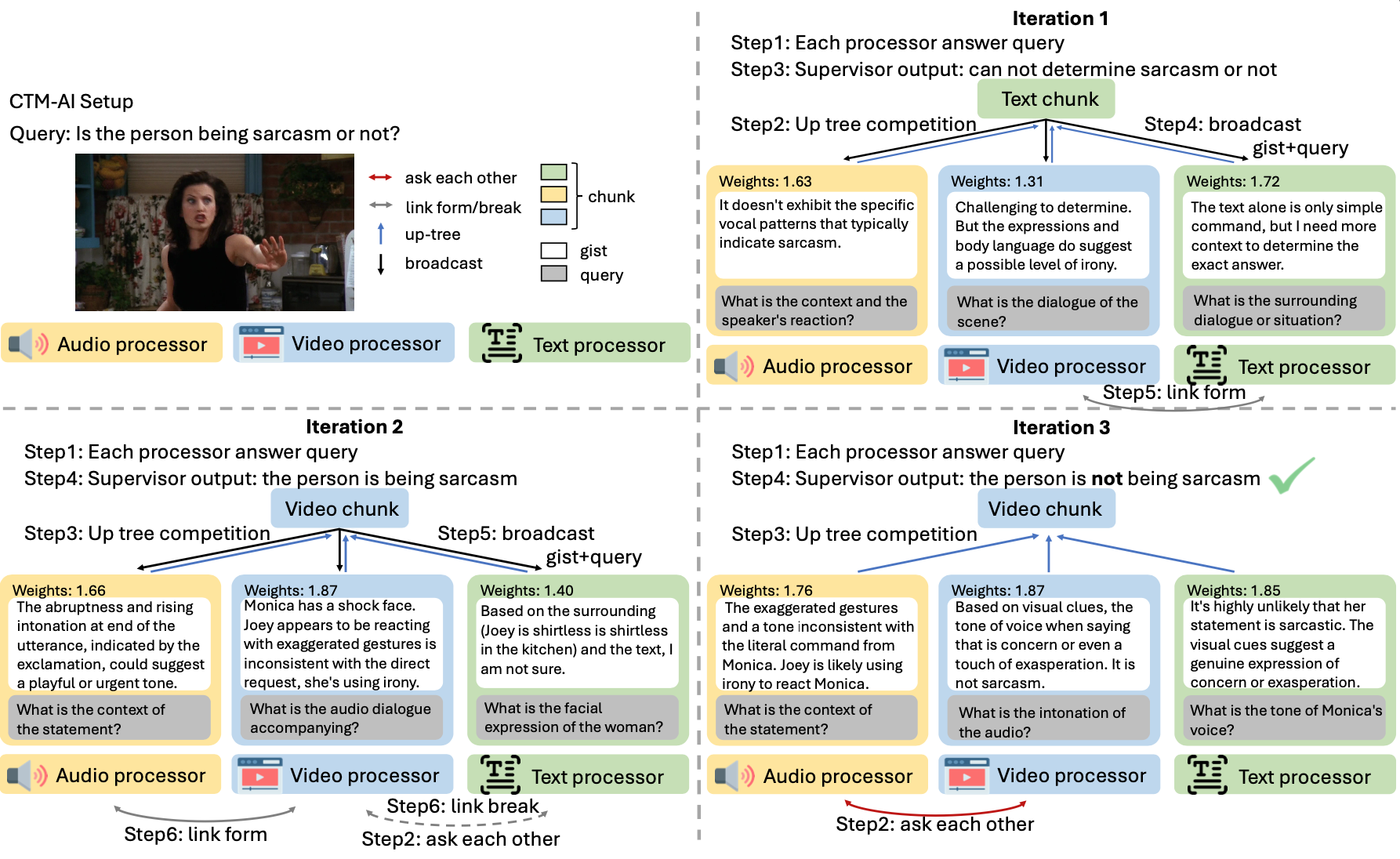
Case Study Snapshot
In a sarcasm example, text/video/audio processors iteratively ask each other for missing context (dialogue, facial expression, tone), links form between relevant processors, and the winning evidence changes across iterations until the system converges.
Foundational CTM References
Key papers on the Conscious Turing Machine and its implications for AI consciousness.
Citation
@misc{ctmai2026,
title = {CTM-AI: A Blueprint for General AI Inspired by a Model of Consciousness},
author = {Haofei Yu and Yining Zhao and Lenore Blum and Manuel Blum and Paul Pu Liang},
year = {2026},
eprint = {2605.04097},
archivePrefix = {arXiv},
primaryClass = {q-bio.NC},
url = {https://arxiv.org/abs/2605.04097}
}
Acknowledgements
This work was done in part while Lenore Blum, Manuel Blum, and Paul Liang were visiting the Simons Institute for the Theory of Computing. We are grateful to our friend Michael Xuan for his enormous personal support and encouragement. We thank UniDT for their supporting grant of our work. We also acknowledge Nvidia’s GPU support.